
This morning I noticed something new in my Chrome Console while working on a Chrome Extension. It looks like Facebook is now looking to see if you have a set of Chrome extensions installed in your browser. Most of the extensions I looked up on Google’s web store and via their search engine and they look like they are Malware of some sort, but a few of them look like they are much less harmless. It’s hard to see what the extensions actually do because they have been pulled from the Chrome Web Store, but some of these look like they modified the appearance of Facebook intentionally.
Some users don’t like being forced to see walmart colors all over the web and have used various tactics to customize the web to their liking. Some other users might do it for usability reasons or just plain augmentation of the web.
Does Facebook have the right to do this? It feels like an invasion of my privacy. I think the latest version of Chrome protects us from this sort of attack but that does not mean that Facebook won’t invest in other ways to discover this information or that they won’t lobby google to discover it. Some extensions also have the ability to open up channels to other extensions so if facebook had it’s own extension it might still try to fingerprint which extensions are there.
This isn’t all bad, in fact it really depends on how it’s being used. If it’s only used to defend our privacy and security then it seems fine, but if this little trick is being abused this could really sour things.
I guess I am mostly just surprised that Facebook is doing this.
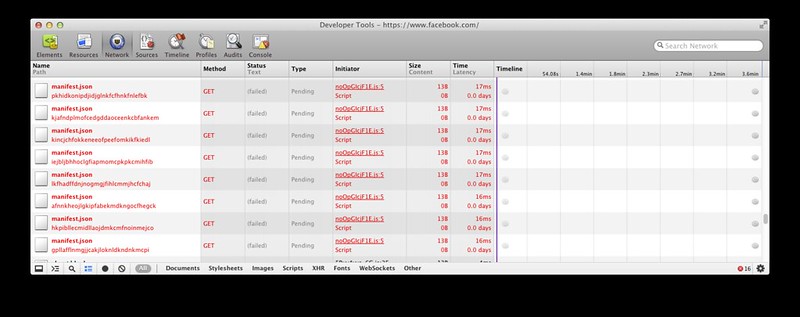
To get this to occur in your own browser you will need to be a bit sneaky and use a private session. Once Facebook runs the finger print they don’t do it all of the time, I think they only do it on auth and then they cache the result in some way. In fact since some extensions have access to the cookies I wonder if one could ‘skip’ the finger printing by setting the proper cookies or localstorage setting.
Finger Printed Extension IDs
kjafndplmofcedgddaoceenkcbfankem kincjchfokkeneeofpeefomkikfkiedl iejbljbhhoclgfiapmomcpkpkcmihfib lkfhadffdnjnogmgjfihlcmmjhcfchaj afnnkheojlgkipfabekmdkngocfhegck hkpibllecmidllaojdmkcmfnoinmejco gpllafflnmgjjcakjloknldkndnkmcpi pkhidkonipdjidjglnkfcfhnkfnlefbk kjafndplmofcedgddaoceenkcbfankem kincjchfokkeneeofpeefomkikfkiedl iejbljbhhoclgfiapmomcpkpkcmihfib lkfhadffdnjnogmgjfihlcmmjhcfchaj afnnkheojlgkipfabekmdkngocfhegck hkpibllecmidllaojdmkcmfnoinmejco gpllafflnmgjjcakjloknldkndnkmcpi
Recent Comments